Can obfuscation affect performance?
Almost every commercial application nowadays uses code protection. Traditionally, .NET applications are protected by obfuscation. An obfuscator renames metadata, changes the code, making it difficult to decode, hides resources, encrypts string literals, and so on.
This approach looks very attractive, but developers often wonder whether obfuscation affects performance. The question sounds simple, but the answer is not obvious at all. As usual, “the devil is in the detail” what kind of obfuscation has been used.
In this article, using some exact examples, we will have a look at how different obfuscation methods affect performance and draw conclusions about which of them should be used and when.
Although we consider a certain platform, .NET, the findings of this study can be applied to other environments such as Java; that’s to be expected because the principles of code protection are platform-independent.
As an example in this article, we will take the implementation of the cryptographic hash function sha256, in C#. The project has four classes that calculate the hash. All the classes contain the same code, differing only in which obfuscation method is applied to the methods.
The project is available on GitHub: https://github.com/Softanics/ObfuscationSpeedTest
The program will calculate the hash 1000 times using each of the classes. Then it will display the execution time of each obfuscation method and the speed difference between the original code and the obfuscated code execution time.
In our test we’ve got the following numbers:
Without obfuscation: 0.02298607 ms Names obfuscation: 0.02341139 ms (+1%) Control flow obfuscation: 0.06654356 ms (+189%) Virtualization: 1.5812997 ms (+6779%)
Names obfuscation
The very first obfuscators did nothing but change the names of public classes, properties, fields, etc. This method is really simple, but quite effective because the information about the names of classes and methods allows you to understand well what the code is doing. Names such as ShowNagScreen and IsSerialKeyValid speak for themselves!
What can we say about the impact of metadata renaming on the speed of obfuscated code execution? The speed practically does not change, and it is easy to understand why: after all, the method code itself remains the same:
Names obfuscation: 0.02341139 ms (+1%)
Control Flow Obfuscation
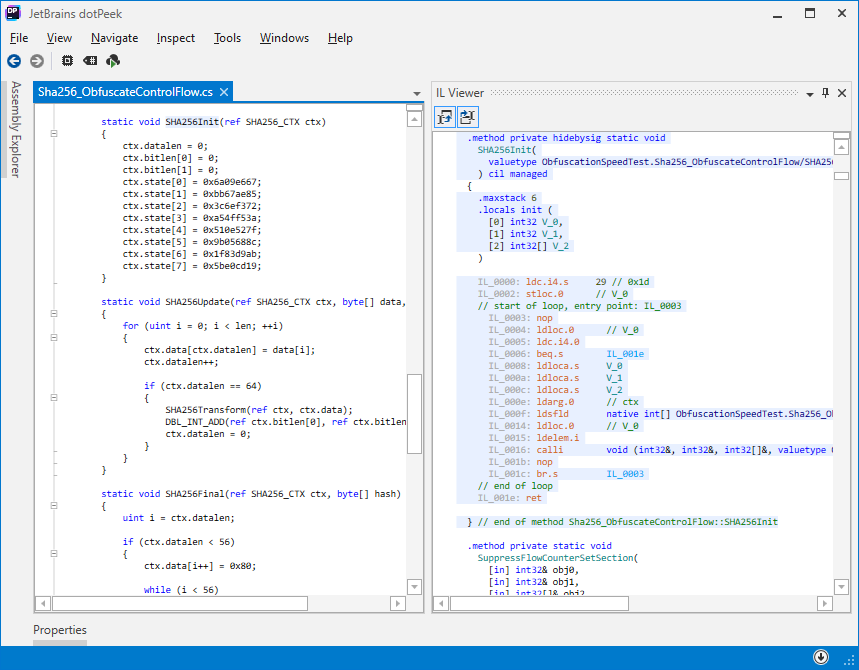
This approach extracts all branches from the original code into separate methods (each is assigned an index). After obfuscation, the method is presented as a loop that calls these methods one in a time.
If this approach it is difficult to restore the original code because it’s necessary to find all methods for each branch, as well as to understand the logic of calculating the index for the next method.
ArmDot uses the calli instruction, which slows down the execution (+ 189% in our example), since calling by pointer method is slower than a normal call. In addition, JIT does not have such broad capabilities for optimizing intermediate code, since in this case, the JIT is forced to optimize each method separately:
Code Virtualization
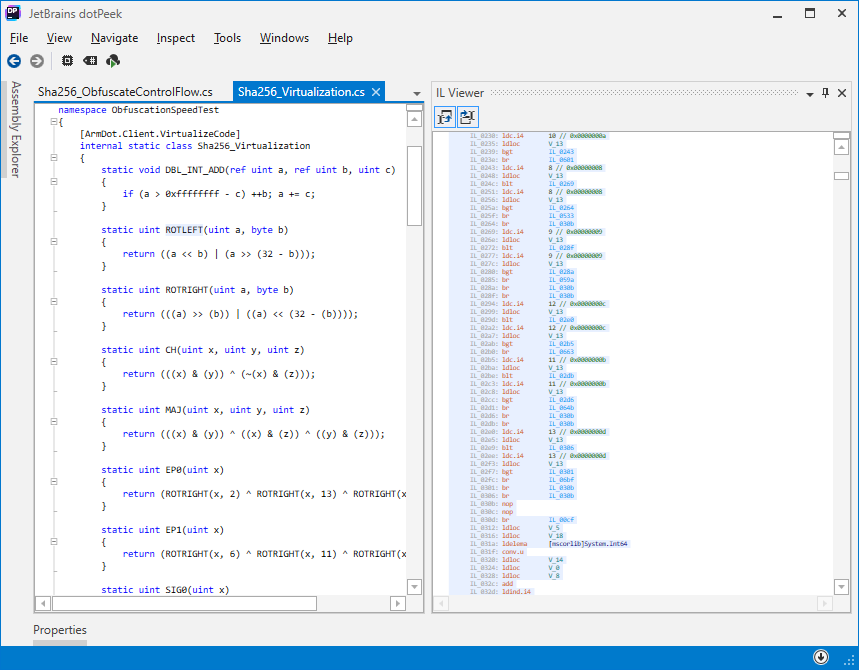
Code virtualization is the most advanced virtualization approach, but also the most expensive in terms of performance. Each instruction of the original code is encoded for execution on a virtual processor. Thus, it turns out that the original code is interpreted, which is always slow. In our example, the speed is reduced by about 60 times. This is the price to pay for the fact that it is almost impossible to deobfuscate the virtualized code:
Conclusions
- The more advanced obfuscation is used, the slower the obfuscated code is executed.
- Name obfuscation does not affect the performance and should always be used.
- You can virtualize methods that are not computationally intensive. Otherwise, control flow obfuscation should be used.